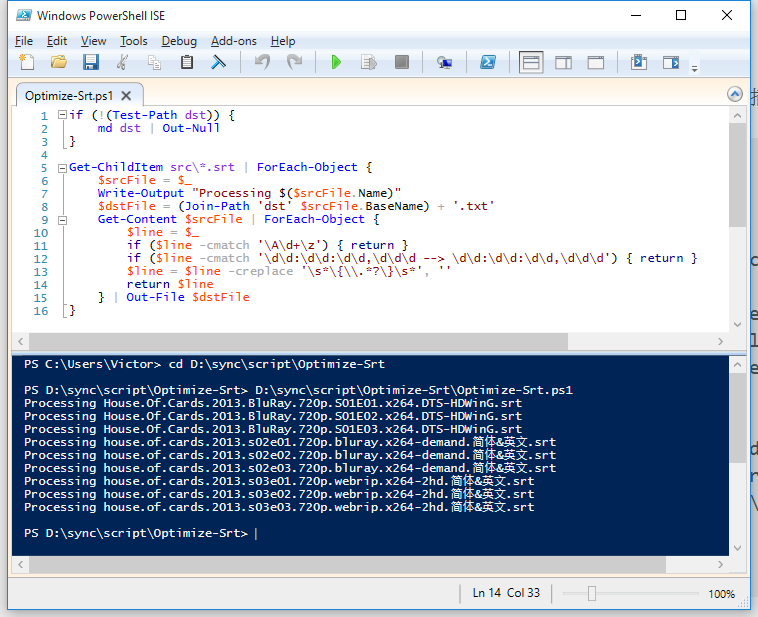
电骡的 eD2k 链接包含了丰富的信息。例如这个:
ed2k://|file|BingPinyinSetup_1.5.24.02.exe|31485072|C8C9282E6112455E624EE82941E5BA00|p=79A822E1788353E0B289D2ADD5DA3BDE:FB9BB40DEDB1D2307E9D734A6416704B:0732B122C4ECF70065B181C92BF72400:437958DF590D764DE1694F91AC085225|h=HLXRQSANEO5MHIVOYNM5FNQOHJG3D5MP|s=http://blog.vichamp.com|s=http://www.baidu.com|/|sources,127.0.0.1:1234,192.168.1.1:8888|/
这给我们的第一感觉是可以用正则表达式来解析。我们观察一下它的规律,发现它是用 | 分割的字符串:
ed2k://
file
BingPinyinSetup_1.5.24.02.exe
31485072
C8C9282E6112455E624EE82941E5BA00
p=79A822E1788353E0B289D2ADD5DA3BDE:FB9BB40DEDB1D2307E9D734A6416704B:0732B122C4ECF70065B181C92BF72400:437958DF590D764DE1694F91AC085225
h=HLXRQSANEO5MHIVOYNM5FNQOHJG3D5MP
s=http://www.abc.com/def.zip
s=http://www.vichamp.com/qq.zip
/
sources,127.0.0.1:1234,192.168.1.1:8888
/
还有一些规律:
- 从
p= 开始,后面的段都是可选的。
p=xxx、h=xxx、s=xxx看起来像键值对。s= 可以有多个,sources 后面的 IP 和端口可以有多对。
根据这个规律,我们可以很容易地构造出正则表达式,并用 PowerShell 解析它。
function Get-Ed2kLink {
Param(
[string]
[Parameter(Mandatory = $true, ValueFromPipeline = $true, HelpMessage = 'Enter an ed2k:// url')]
$Link
)
$regex = [regex]@'
(?x)
\bed2k://
\|file\|(?<FILE_NAME>[^|]+)
\|(?<FILE_SIZE>\d+)
\|(?<FILE_HASH>[0-9a-fA-F]+)
(?:\|p=(?:(?<HASH_SET>[0-9a-fA-F]+):?)+)?
(?:\|h=(?<ROOT_HASH>[0-9a-zA-Z]+))?
(?:\|s=(?<HTTP_SOURCE>[^|]+))*
\|\/
\|sources(?:,(?<SOURCES_HOST>[0-9a-zA-Z.]+):(?<SOURCES_PORT>\d+))*
|\/\b
'@
$match = $regex.Match($Link)
if ($match.Success) {
$sourcesHost = $match.Groups['SOURCES_HOST'].Captures | Select-Object -ExpandProperty Value
$sourcesPort = $match.Groups['SOURCES_PORT'].Captures | Select-Object -ExpandProperty Value
$sources = @()
for ($i = 0; $i -lt $sourcesHost.Length; $i++) {
$sources += [PSCustomObject][Ordered]@{
Host = $sourcesHost[$i]
Port = $sourcesPort[$i]
}
}
$result = [PSCustomObject][Ordered]@{
File = $match.Groups['FILE_NAME'].Value;
FileSize = $match.Groups['FILE_SIZE'].Value;
FileHash = $match.Groups['FILE_HASH'].Value;
HashSet = $match.Groups['HASH_SET'].Captures | Select-Object -ExpandProperty Value
RootHash = $match.Groups['ROOT_HASH'].Value;
HttpSource = $match.Groups['HTTP_SOURCE'].Captures | Select-Object -ExpandProperty Value
Sources = $sources;
}
} else {
$result = $null
}
return $result
}
Get-Ed2kLink 'ed2k://|file|BingPinyinSetup_1.5.24.02.exe|31485072|C8C9282E6112455E624EE82941E5BA00|p=79A822E1788353E0B289D2ADD5DA3BDE:FB9BB40DEDB1D2307E9D734A6416704B:0732B122C4ECF70065B181C92BF72400:437958DF590D764DE1694F91AC085225|h=HLXRQSANEO5MHIVOYNM5FNQOHJG3D5MP|s=http://www.abc.com/def.zip|s=http://www.vichamp.com/qq.zip|/|sources,127.0.0.1:1234,192.168.1.1:8888|/'
执行结果如下:
File : BingPinyinSetup_1.5.24.02.exe
FileSize : 31485072
FileHash : C8C9282E6112455E624EE82941E5BA00
HashSet : {79A822E1788353E0B289D2ADD5DA3BDE, FB9BB40DEDB1D2307E9D734A6416704B, 0732B122C4ECF70065B181C92BF72400, 437958DF590D764DE1694F91AC085225}
RootHash : HLXRQSANEO5MHIVOYNM5FNQOHJG3D5MP
HttpSource : {http://www.abc.com/def.zip, http://www.vichamp.com/qq.zip}
Sources : {@{Host=127.0.0.1; Port=1234}, @{Host=192.168.1.1; Port=8888}}
注意一下,由于 s= 和 sources 节包含循环体,所以不能直接用 PowerShell 的 -cmatch 表达式和 $Matches 变量,必须用 .NET 的 [regex] 类来处理。
参考材料:
您也可以在这里下载完整的源代码。